Extensions > Geostatistical Analyst > Deterministic methods
How Inverse Distance Weighted (IDW) interpolation works |
|
|
Release 9.2
Last modified August 7, 2007 |
Print all topics in : "Deterministic methods" |
IDW interpolation explicitly implements the assumption that things that are close to one another are more alike than those that are farther apart. To predict a value for any unmeasured location, IDW will use the measured values surrounding the prediction location. Those measured values closest to the prediction location will have more influence on the predicted value than those farther away. Thus, IDW assumes that each measured point has a local influence that diminishes with distance. It weights the points closer to the prediction location greater than those farther away, hence the name inverse distance weighted.
See Using ArcGIS Geostatistical Analyst for formula and additional information.
Learn more about the interpolation techniques available in ArcGIS Geostatistical Analyst
The Power function
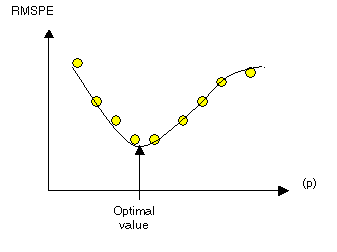
The optimal power (p) value is determined by minimizing the root mean square prediction error (RMSPE). The RMSPE is the statistic that is calculated from cross-validation. In cross-validation, each measured point is removed and compared to the predicted value for that location. The RMSPE is a summary statistic quantifying the error of the prediction surface. Geostatistical Analyst tries several different powers for IDW to identify the power that produces the minimum RMSPE. The diagram below shows how Geostatistical Analyst calculates the optimal power. The RMSPE is plotted for several different powers for the same dataset. A curve is fit to the points (a quadratic Local Polynomial equation), and from the curve the power that provides the smallest RMSPE is determined as the optimal power.
Weights are proportional to the inverse distance raised to the power value p. As a result, as the distance increases, the weights decrease rapidly. How fast the weights decrease is dependent on the value for p. If p = 0, there is no decrease with distance, and because each weight λi will be the same, the prediction will be the mean of all the measured values. As p increases, the weights for distant points decrease rapidly. If the p value is very high, only the immediate few surrounding points will influence the prediction.
Geostatistical Analyst uses power functions greater than 1. A p = 2 is known as the inverse distance squared weighted interpolation.
The search neighborhood
Because things that are close to one another are more alike than those farther away, as the locations get farther away, the measured values will have little relationship with the value of the prediction location. To speed calculations you can discount to zero the more distant points with little influence. As a result, it is common practice to limit the number of measured values that are used when predicting the unknown value for a location by specifying a search neighborhood. The specified shape of the neighborhood restricts how far and where to look for the measured values to be used in the prediction. Other neighborhood parameters restrict the locations that will be used within that shape. In the following image, five measured points (neighbors) will be used when predicting a value for the location without a measurement, the yellow point.
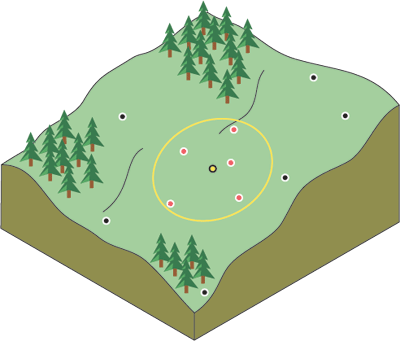
The shape of the neighborhood is influenced by the input data and the surface you are trying to create. If there are no directional influences on the weighting of your data, you'll want to consider points equally in all directions. To do so, you'll probably want the shape of your neighborhood to be a circle. However, if there is a directional influence on your data, such as a prevailing wind, you may want to adjust for it by changing the shape of your neighborhood to an ellipse with the major axis parallel with the wind. The adjustment for this directional influence is justified because you know that locations upwind from a prediction location are going to be more similar at remote distances than locations that are perpendicular to the wind.
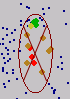
Once a neighborhood shape is specified, you can restrict which locations within the shape should be used. You can define the maximum and minimum number of locations to use, and you can divide the neighborhood into sectors. If you divide the neighborhood into sectors, the maximum and minimum constraints will be applied to each sector. There are several different sectors that can be used and are displayed below.
![]()
The points highlighted in the data view of the Searching Neighborhood dialog box identify the locations and the weights that will be used for predicting a location at the center of the ellipse. The neighborhood is contained within the displayed ellipse. In the following example, two points (red) in the sector to the west and one point in the southern sector will be weighted more than 10 percent. In the northern sector, one point (yellow) will be weighted between 3 percent and 5 percent.
When to use IDW

The surface calculated using IDW depends on the selection of a power value (p) and the neighborhood search strategy. IDW is an exact interpolator, where the maximum and minimum values (see diagram above) in the interpolated surface can only occur at sample points. The output surface is sensitive to clustering and the presence of outliers. IDW assumes that the surface is being driven by the local variation, which can be captured through the neighborhood.