Extensions > Spatial Analyst > Analysis concepts > Distance analysis
Understanding cost distance analysis |
|
|
Release 9.2
Last modified May 2, 2007 |
Print all topics in : "Distance analysis" |
Cost distance tools calculate for each cell the least accumulative cost to specified source locations over a cost surface. A source and a cost must be created. Cost distance is the prerequisite for finding the least cost path or corridor.
Learn how to calculate cost weighted distance, direction, and allocation using the Spatial Analyst toolbar
Learn how to calculate cost weighted distance using the Cost Distance tool
Learn how to calculate cost weighted direction using the Cost Back Link tool
Learn how to calculate cost weighted allocation using the Cost Allocation tool
Finding the least-cost route for a road using the Cost Distance function
In the following example, the Cost Distance functions are used to find the least-cost path for a new road. The Cost Distance function is the prerequisite to the Cost Path function. The Cost Path function determines the road's actual route.
To calculate the least accumulative cost from each cell to the nearest source, the Cost Distance function needs a source and a cost raster.
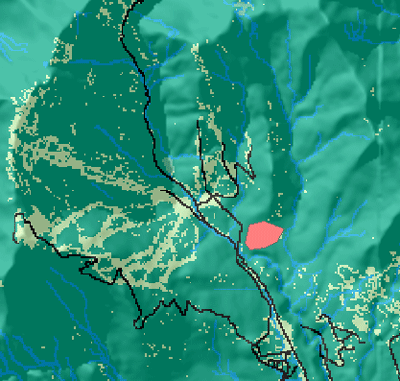
The source
The source is the starting point of your proposed feature for analysis. For example, in the graphic below, you can see the starting point (in red) for the proposed road.
The cost raster
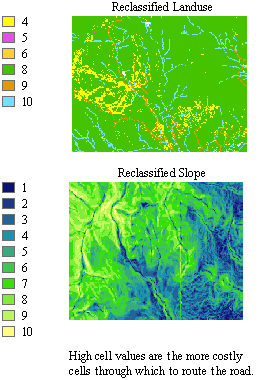
The cost raster identifies the cost of traveling through each cell. To create this raster, you need to identify the cost of constructing a road through each cell. Although the cost raster is a single dataset, it is often used to represent several criteria. In the following example, land use and slope influence the construction costs. Each of these datasets is in a different measurement system (land use type and percent slope), so they cannot be compared to one another and must be reclassified to a common scale.
Creating a cost raster
Reclassifying your datasets to a common scale
In this example, slope and land use have been reclassified on a scale of 1 to 10. The attributes of each dataset should be examined to determine their contribution to the cost of building a road. For example, it is more costly to traverse steep slopes, so steeper slopes will be assigned higher costs when reclassifying this dataset. The graphics below display the results.
Weighting datasets according to percent influence
The next step in producing the cost raster is to add the reclassified datasets together. The simplest approach is to just add them together. However, some factors may be more important than others. For instance, avoiding steep slopes may be twice as important as the land use type, so you might give this dataset an influence of 66 percent and the land use dataset an influence of 34 percent (to equal 100 percent). The following diagram shows the conceptual process:
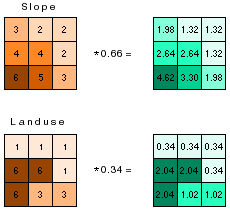
Combining the datasets
The final cost raster is the result of adding together the weighted datasets.

The following diagram shows the final cost raster, the result of reclassifying the datasets of slope and land use; weighting each by 0.66 and 0.34, respectively; then combining the weighted datasets.

The Cost Distance function
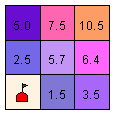
Using the cost raster and the source, the Cost Distance function produces an output raster in which each cell is assigned a value that is the least accumulative cost of getting back to the source.
Using the previous example, this function takes the cost raster and calculates a value for each cell in the output cost-weighted raster that is the accumulated least cost of getting from that cell to the nearest source.
Every cell in the cost-weighted raster is assigned a value representing the sum of the minimum travel costs that would be incurred by traveling back along the least-cost path to its nearest source.
In the example below, the accumulated least costly way of getting from the cell colored dark orange to the school is 10.5.
Direction
The cost distance raster tells you the least accumulated cost of getting from each cell to the nearest source, but it doesn't tell you how to get there. The direction raster provides a road map, identifying the route to take from any cell, along the least-cost path, back to the nearest source.
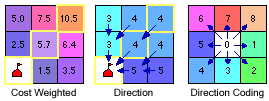
The algorithm for computing the direction raster assigns a code to each cell that identifies which one of its neighboring cells is on the least-cost path back to the nearest source. In the direction coding diagram above, 0 represents each processing cell in the accumulative cost raster. Each cell is assigned a value representing the direction of the nearest, cheapest cell on the route of the least costly path to the nearest source.
For example, in the graphic above, the cheapest way to get from the cell with a value of 10.5 to the source (the school site) is to go diagonally, through the cell with a value of 5.7. The direction algorithm assigns a value of 4 to the cell with a value of 10.5, and 4 to the cell with a value of 5.7, because (from the directional coding described above) this is the direction of the least-cost path back to the source from each of these cells. This process is done for all cells in the cost distance raster, producing the direction raster, which tells you the direction to travel from every cell in the cost distance raster back to the source.
Both the cost distance and direction rasters are required if you want to calculate the least-cost (shortest) path between source locations and destination locations.
Allocation
The cost allocation raster identifies the nearest source from each cell in the cost distance raster. It is conceptually similar to the Euclidean allocation function, in which each cell is assigned to its nearest source cell. However, "near" is expressed in terms of accumulated travel cost.