Geodatabases and ArcSDE > Data management workflows, transactions, and versioning > Managing Distributed Data
Preparing data for replication(ArcInfo and ArcEditor only) |
|
|
Release 9.2
Last modified March 25, 2008 |
Print all topics in : "Managing Distributed Data" |
The following steps should be considered when preparing data for replication:
Determine the datasets to replicate
Geodatabase replication allows you to replicate all datasets or a subset of datasets in your geodatabase. In order to be replicated, these datasets must meet the following requirements:
- The database user must have write access to the data.
- All data must be registered as versioned.
- The data cannot be versioned with the option to move edits to base.
Two way and one way replicas have these additional requirements:
- Each dataset must have a Globalid column. This column is used to maintain row uniqueness across geodatabases.
- All spatial data must be stored in a high precision spatial reference.
Any dataset not meeting these requirements will not be included in the replica.
The list of data to replicate will automatically be expanded to include dependent datasets. For example, all feature classes in a geometric network, topology, or feature dataset will be included if just one feature class in the network, topology, or feature dataset is selected for replication.
Define the data to be replicated
For each dataset, you can choose to replicate all data, a subset of rows or even just the schema. Plan on replicating an appropriate amount of data for your needs. Consider the lifetime of the replica and make sure your requirements are covered.
Replica creation determines the data to replicate using two mechanisms: filters and relationship classes.
There are three types of filters:
-
Spatial
- Geometry is used to determine the area to replicate
Selections
- data is replicated based on selection sets on individual feature classes and tables
Querydefs
- definition queries applied to individual feature classes and tables
When replicating in ArcMap, the spatial filter is determined by the current view extent of the ArcMap document or the boundary of a currently selected graphic. Features intersecting this filter are included. Definition queries and selections on individual layers and tables are also applied. If more than one filter is used the intersection of all filters is applied.
Once data has been added to the replica from processing the filters, the relationship class logic is applied. Here, for each dataset involved in a relationship class, additional rows are added if they are related to the data already in the replica. See replicating related data for more information.
The following lists types of data for which additional rules and behaviors are applied when creating replicas. Review the topics that are appropriate for your data:
Geometric Networks
Topologies
Raster Data
Terrains
Network Datasets
Representations
An example of replicating data
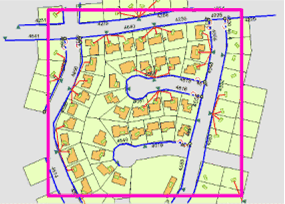
The following electric utilities’ maintenance work orders will help illustrate some of the default behavior for replicating data.
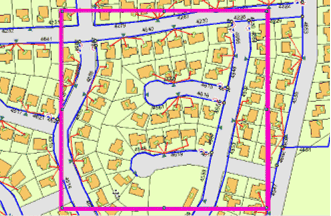
A maintenance crew is preparing to inspect some of the electric utilities in a residential area. To do some field editing, the crew needs to replicate that part of the electric network that covers this residential area. To start the replication process, the spatial extent of the inspection area is identified using a spatial filter (in this case, the extent is determined by a selected graphic).
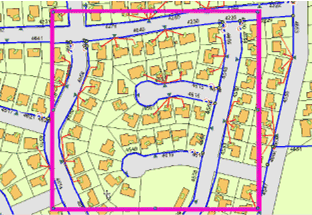
The crew is to concentrate on cables that have been insulated with a particular material. To identify these cables, a query is applied to the relevant dataset.
Finally, as each maintenance crew can expect to visit only a certain number of properties in a day, the homes in one residential block are identified by a selection based on property numbers.
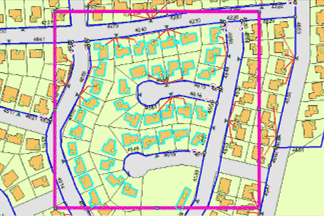
The selected features, features identified by a definition query, and features that intersect the chosen spatial extent will be replicated. Some additional network features have also been included. How geometric networks are replicated is explained in greater detail in Replicating geometric networks.