Tuning and configuring services
Tuning and configuring services |
|
| Release 9.3.1 |
|
ArcGIS Server makes it easy to publish services right away because it sets many of the default service properties for you; however, if hundreds or thousands of users will be accessing your services, or if users will be performing stateful operations such as editing on your services, you'll want to change the default service property values to best accommodate your deployment. This topic provides an overview of some of the properties and techniques that you can use to best configure your services.
You can modify a service's properties to make it either pooled or nonpooled. Instances of a pooled service can be shared between multiple application sessions. When an application session returns a pooled service instance to the server, it is available for use by other application sessions. Therefore, pooled services should only be used with stateless operations.
In contrast, instances of a nonpooled service are dedicated to one application session. An instance of a nonpooled service is destroyed when an application session returns it to the server. Nonpooled services are used when the application needs to perform stateful operations, such as editing with undo/redo enabled.
Both pooled and nonpooled configurations require you to specify a minimum and maximum number of instances when you add the service. When you start the service configuration, the GIS server creates and initializes the minimum number of instances. When an application asks the server object manager (SOM) for an instance of that service, it gets a reference to one of the instances. If all the instances are in use, the server creates a new instance. It will do this for each subsequent request until the maximum allowable number of instances for the configuration has been reached or the capacity of all container machines has been reached, whichever comes first.
An application that uses an instance of a pooled service only uses it for the amount of time it takes to complete one request (for example, to draw a map or geocode an address). After the request is completed, the application releases its reference to the service and returns it directly to the available pool of instances. Users of such an application may be working with a number of different instances of a service in the pool as they interact with the application. This fact is transparent to the users, since the state of all the instances in the pool is the same.
For example, a stateless application that wants to draw a certain extent of a map will get a reference to an instance of a map service from the pool, execute a method on the map service to draw the map, then release it back to the pool. The next time the application needs to draw the map, this is repeated. Each draw of the map may use a different instance of the pooled service; therefore, each instance must be the same (have the same set of layers, the same renderer for each layer, and so on). If you change the state of an instance by, for example, adding a layer or changing a layer's renderer, he or she will see inconsistent results while panning and zooming around the map. This is because the instance whose state was changed was returned to the pool, and you are not guaranteed to receive that particular instance from the pool every time you request a service. It's the developer's responsibility to make sure that the application does not change the state of the instance and that the instance is returned to the pool in a timely manner.
Pooling services allows the GIS server to support more users with fewer resources allocated to a particular service. Because applications can share a pool of instances, the number of concurrent users on the system can be greater than that which would be possible if each user held a reference to a dedicated instance.
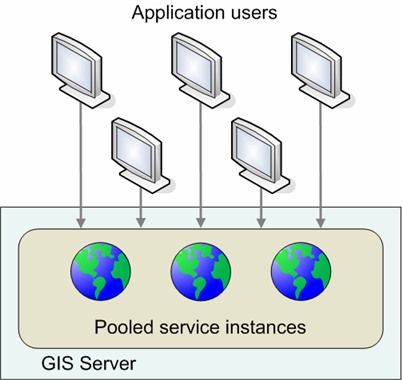
Pooled services can support more users because application sessions share a collection of services in the pool.
An application that makes use of a nonpooled service instance typically holds its reference to the instance for the duration of the application's session. When the application releases the instance, it is destroyed and the GIS server creates a new one to maintain the number of available instances. For this reason, the user of a nonpooled service can make changes to the service's underlying data.
With nonpooled services, the number of users on the system can have no more than a 1:1 correlation with the number of running service instances. Therefore, the number of concurrent users the GIS server can support is equal to the number of nonpooled instances that it can support effectively at any one time.
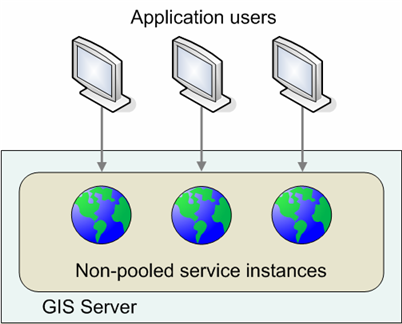
To achieve the most concurrent users possible for your GIS server, avoid using nonpooled services unless you need them for stateful operations such as Web editing of versioned data. When you develop applications with nonpooled services, make sure you destroy the service instances when they are no longer needed. If you are building a Web editing application in Manager that uses nonpooled services, encourage your users to click the Close link when they exit the application. Doing so ensures that the nonpooled service instances will be destroyed immediately, instead of when they time out.
Service recycling allows services that have become unusable to be destroyed and replaced with fresh services; recycling also reclaims resources taken up by stale services.
Pooled services are typically shared between multiple applications and users of those applications. Through reuse, a number of things can happen to a service to make it unavailable for use by applications. For example, an application may incorrectly modify a service's state, or an application may incorrectly hold a reference to a service, making it unavailable to other applications or sessions. In some cases, services may become corrupted and unusable. Recycling allows you to keep the pool of services fresh and cycle out stale or unusable services. Note that recycling does not apply to nonpooled services because nonpooled services are created explicitly for use by a particular client and destroyed after use.
During recycling, the server destroys, then re-creates, each instance in a pooled service configuration. Recycling occurs as a background process on the server. Although you will not see anything on your screen notifying you that recycling is occurring, you can see the events associated with recycling in the log files.
Recycling destroys and re-creates all running instances of a service, whether or not those instances are above the minimum specified. To periodically return the number of running instances to the minimum specified, the service must be stopped and restarted. A good way to automate this process is to create a Python, shell, or Windows batch script that executes a custom ArcGIS Server API command line executable file. This custom executable file would take the server name, service name, service type, and whether the service should be started or stopped as command line arguments. It would be implemented using IServerObjectAdmin.StartConfiguration and IServerObjectAdmin.StopConfiguration.
The time between recycling events is the recycling interval. The default recycling interval is 24 hours, which you can change on the Service Properties dialog box. You can also choose the time that the configuration will initially be recycled. From that time forward, recycling will occur each time the recycling interval is reached.
Services are recycled one instance at a time to ensure that instances remain available and to spread out the performance hits caused by creating a new instance of each service. Recycling occurs in random order; however, instances of services in use by clients are not recycled until released. In this way, recycling occurs without interrupting the user of a service.
If there are not enough services available during recycling, a request will be queued until an instance becomes available. If the MaximumWaitTime is reached during this time, the log files will record the same message that they normally would.
If you change the underlying data of a service, this change will automatically be reflected after recycling. For example, if you have a service of type MapServer running and you change its associated map document, you will be able to see the change after recycling occurs. (To see the changes immediately, you can manually stop and start the service.)
When you create a service, you specify the minimum and maximum number of instances you want to make available. These instances run on the container machines within processes. The isolation level determines whether these instances run in separate processes or shared processes.
With high isolation, each instance runs in its own process. If something causes the process to fail, it will only affect the single instance running in it.
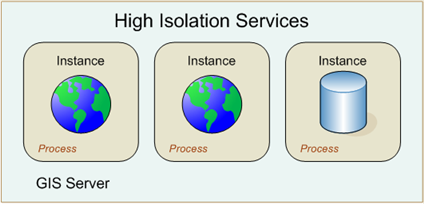
Services with high isolation run in dedicated processes on the GIS server.
In contrast, low isolation allows multiple instances of a service configuration to share a single process, thus allowing the execution of four concurrent, independent requests. This is often referred to as multi-threading.
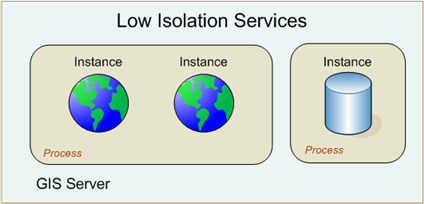
With low isolation, a default of 8 instances and a maximum of 256 instances of the same service configuration can share a process. You can set the number of instances per process on the Processes tab of the Service Properties dialog box. When this number of instances of a particular service are created, the server starts an additional process for the next group of instances, and so on. As instances are created and destroyed, they will vacate and fill spaces in those running processes.
The advantage of low isolation is that it increases the number of concurrent instances supported by a single process. Using low isolation can significantly improve memory consumption on your server. However, this improvement comes with some risk. If a process experiences a shutdown or crash, all instances sharing the process will be destroyed. Low isolation also reduces the effectiveness of pool shrinking because all instances in a process must go out of use before pool shrinking can remove the process.
Note that nonpooled services always run in their own process; thus, isolation level does not apply.
Once a client gets a reference to a service, it uses the service for a certain period of time before releasing it. The amount of time between when a client gets a reference to a service and when it releases it is the usage time. To ensure that clients don't hold references to services for too long (that is, they don't correctly release services), each service has a maximum time a client can use a service. If a client holds on to a service for longer than the maximum usage time, the service is automatically released and the client loses its reference to the service.
Maximum usage time also protects services from being used to do larger volumes of work than the administrator intended. For example, a service that is used by an application to perform geodatabase checkouts might have a maximum usage time of 10 minutes. In contrast, a service that is used by applications that only draw maps might have a maximum usage time of 1 minute.
When the maximum number of instances of a pooled or nonpooled service is in use, a client requesting a service will be queued until another client releases one of the services. The amount of time it takes between a client requesting a service and getting a service is the wait time. Each service has a maximum time a client will wait to get a service. If a client's wait time exceeds the maximum wait time for a service, then the request will time out.
A third time-out dictates the maximum time an idle instance can be kept running. When services go out of use, they are kept running on the server until another client needs the instance. A running instance that is not in use still consumes some memory on the server. You can minimize your number of running services and therefore conserve memory by shortening this idle time-out, the default of which is 1,800 seconds (30 minutes). The disadvantage of a short idle time-out is that when all running services time out, subsequent clients need to wait for new instances to be created.
When services are created in the GIS server, either as a result of the server starting or in response to a request for a server by a client, the time it takes to initialize the service is referred to as its creation time. The GIS server maintains a startup time-out that dictates the amount of time that can elapse on a startup attempt before the GIS server will assume its startup is hanging and cancel the creation of the service. This property is only configurable through manually editing the service configuration file.
The GIS server maintains statistics both in memory and in its log files about wait time, usage time, and other events that occur within the server. The server administrator can use these statistics to determine if, for example, the wait time for a service is high, which may indicate a need to increase the maximum number of instances for that service.
Capacity limits the number of service instances that can run on a server object container (SOC) machine. By default, capacity is unlimited. However, if you have a machine with limited memory, you can set a capacity limit to make sure the memory footprint of the running instances doesn't overwhelm the machine.
Once the number of running service instances on a SOC reaches the capacity, the server will not create any new instances on that machine. If all SOC machines have reached capacity, then pool shrinking takes effect.
When choosing capacity values, be careful not to confuse running instances with "in use" instances. Running instances consume memory but not CPU power. In-use instances consume memory and CPU. A server that may only be able to support four "in use" instances at a time may be able to support many more than four running instances if it has sufficient RAM. You might want these instances to be running so that they are available immediately at any time.
If you have plenty of memory on a machine, you should leave capacity set to Unlimited.
Technical notes:
What happens when a GIS server reaches capacity on all its container machines? ArcGIS Server uses the concept of pool shrinking, which removes service instances of less popular configurations and replaces them with instances of the more popular configurations.
Pool shrinking takes effect when the number of running service instances has reached capacity on each SOC machine. When this has happened and the SOM receives a request for a service, the server creates the requested instance and destroys one instance of the least recently used service configuration. The following points explain in more detail the capabilities and limitations of pool shrinking:
To make it easy to control how your Web services are used, each type of service has a set of allowed operations. Each operation consists of a set of methods that can be enabled or disabled as a group. Clients of the Web service can only call the methods of the operations that have been allowed.
Suppose you wanted to allow consumers of a mapping Web service to draw the map but not to query the data sources of the map's layers. You would then need to disable the Query operation and ensure that the Map operation is allowed.
If you create a service using the Add New Service wizard (as opposed to the Publish GIS Resource wizard) you can choose the allowed operations as you create the service. No matter how you originally created a service, you can change which operations are allowed on an existing service by editing the service's properties. The available operations are listed on the Capabilities tab of the Service Properties.
The following tables list which methods are included in each operation:
| Map | Query | Data |
|---|---|---|
| GetDocumentInfo | Identify | Find |
| GetLegendInfo | QueryFeatureCount | QueryFeatureData |
| GetMapCount | QueryFeatureIDs | |
| GetMapName | QueryHyperlinks | |
| GetDefaultMapName | GetSQLSyntaxInfo | |
| GetServerInfo | ||
| GetSupportedImageReturnTypes | ||
| ExportMapImage | ||
| IsFixedScaleMap | ||
| ToMapPoints | ||
| FromMapPoints | ||
| HasSingleFusedMapCache | ||
| GetTileCacheInfo | ||
| GetMapTile | ||
| HasLayerCache | ||
| GetLayerTile | ||
| GetVirtualCacheDirectory | ||
| GetCacheName | ||
| ComputeScale | ||
| ComputeDistance |
The default allowed operations for map services are Map, Query, and Data.
| Geocode | ReverseGeocode |
|---|---|
| GeocodeAddress | ReverseGeocode |
| GeocodeAddresses | |
| StandardizeAddress | |
| FindAddressCandidates | |
| GetAddressFields | |
| GetCandidateFields | |
| GetIntersectionCandidateFields | |
| GetStandardizedFields | |
| GetStandardizedIntersectionFields | |
| GetResultFields | |
| GetDefaultInputFieldMapping | |
| GetLocatorProperties |
The default allowed operations for geocode services are Geocode and Reverse Geocode.
| Query | Extraction | Replication |
|---|---|---|
| Get_Versions | ExpandReplicaDatasets | CreateReplica |
| Get_DefaultWorkingVersion | ExtractData | ExportAcknowledgement |
| Get_DataElements | ExportReplicaDataChanges | |
| Get_MaxRecordCount | ImportAcknowledgement | |
| TableSearch | ImportReplicaDataChanges | |
| GetNextResultPortion | ReExportReplicaDataChanges | |
| Get_Replicas | UnregisterReplica | |
| Get_WrappedWorkspaceType | ImportData |
The default allowed operations for geodata services are Query and Extraction, which enable all the supported methods for querying and extracting data. The Replication choice enables all the supported methods for synchronization, data changes, message acknowledgement, and schema.
| Globe | Animation | Query |
|---|---|---|
| Get_Version | Get_Animation | Identify |
| Get_LayerCount | Find | |
| Get_LayerInfos | ||
| Get_LegendInfos | ||
| Get_Config | ||
| Get_MQT | ||
| Get_Configuration | ||
| Get_Tile | ||
| Get_Symbols | ||
| Get_Textures | ||
| Get_VirtualCacheDirectory |
The default allowed operations for globe services are Globe, Animation, and Query. Unlike with map services, the Query operation covers both Identify and Find.