ArcSDE XML columns always have a full document index. The XML document table stores the original XML document and also a copy of the document's content with the XML markup removed. A database text index is created on the document's content without XML markup. This index lets a search quickly find all documents that contain a given word or phrase, such as "population," anywhere in the text.
ArcSDE XML columns may optionally have an XPath index as well. XPath is a language used to identify specific parts of an XML document. An XML column's XPath index is created from an index definition that uses XPath notation to identify the elements and attributes in the column's XML documents that can be searched. Each XML column can use a different index definition to build its XPath index.
An XML column's XPath index can be created and managed using ArcObjects; if you are using an Enterprise geodatabase, it can also be created and managed using the sdexml administrative command.
For example, suppose documents in the XML column describe a feature's source and the documents include an accuracy element that stores a number indicating the accuracy of the source in meters. Building an XPath index that includes the accuracy element would let you find all the features whose source accuracy is greater than a given value.
The XPath index should only include elements and attributes in the XML documents that are available to be searched by a client application. Keeping the XPath index small will improve the XML column's performance. By default, an XML column will not have an XPath index. If you don't need to search individual XML elements or attributes, there is no need to create an XPath index.
If you do create an index definition, you must specify not only which XML elements and attributes, or XPaths, will be indexed but also how their values will be indexed. Each XPath is assigned a data type that is appropriate to the type of content it contains. Each XPath can be indexed as a number, as a short character string, or using a database text index. These are discussed in more detail below.
The XPath index is really a collection of numeric, character, and text indexes. When an XML document is stored, it is checked to see if it contains any of the elements or attributes in the column's XPath index definition. If so, the content of those XPaths is extracted from the document and added to a text, character, or numeric index depending on the data type of the XPath in the index definition.
About database text indexes
One of the advantages to storing information in XML documents is being able to use database text indexing and searching functionality to search those documents. Text indexes can provide better search results for large amounts of text and shorter text that has a large amount of variation between documents. Text indexes use linguistic analysis when matching the search phrase to the document's content and typically use relevance ranking to order the results based on the quality and frequency of those matches.
When the database builds a text index, it evaluates the original text and includes words in the index based on the indexing rules and database settings that are in place. Typically, words that have meaning, such as "river," "pollution," and "population," will be included in the text index, but words such as "and," "the," and "in" won't be included. Words may be indexed so searching with the word "fishing" would also match the words "fish," "fished," and "fisher"; this is known as stemming. Stemming is just one example of the advanced text indexing and searching methods that databases typically provide.
Each database may use different rules or algorithms to index the same text and may therefore produce different results with the same data. Also, each database may use different text indexing methods by default; for example, stemming may be performed by default in one database while in another database it must be enabled. Review the text indexing documentation for your database and set the database and the DBTUNE configuration parameters properly to achieve the desired results for your XML column.
Different rules are used to index text written in different languages. For example, the words that are left out of the text index will be different in English and French such as "et," "le," and "dans." Also, what defines a word is different in some languages; Western languages typically define a word as all the text between two spaces, but different rules may be used in German, Asian, and other languages where the text between two spaces may be a phrase. Different databases may support different languages for text indexing, and all text indexing methods may not be available in all languages.
All documents in an XML column must contain text in the same language. The database text indexing components and the DBTUNE configuration parameters must be properly configured for that language in those XML documents to be indexed and searched correctly. The language used for text indexing may have to be configured separately from other language settings in the database.
Different databases approach text index updates in different ways. When a new XML document is stored in an XML column, the full text of the document and the content of any XPaths handled with a database text index will have their values extracted from the document and stored in the appropriate places. However, by default the database may not immediately process and analyze the text and then update the text indexes. This is generally a good thing. If many documents containing a lot of text are added to or updated in an XML column, the resources required to index the new text may decrease the performance of other database applications.
XPath index definition data types
In the XPath index, document content may be included in a text, character, or numeric index; this corresponds to the data types STRING, VARCHAR, and DOUBLE in the XPath index definition. If an XPath's data type is STRING, content in that element or attribute is indexed using a text index. XPaths with the data type VARCHAR will have their content placed in a regular character column and indexed as they would be in a typical database table. XPaths with the data type DOUBLE will have their values placed in a numeric column and indexed. An XPath index data type is not provided for dates.
When new documents are published, you can find them right away with searches evaluated using XPaths indexed as VARCHAR or DOUBLE. You will not be able to find new documents with searches against XPaths indexed as STRING (or the full document text index) until the database's text indexes have been updated to include information from the new documents.
Choosing STRING or VARCHAR for an XPathIf the domain of an XPath will always be a short string or a word or phrase from a list, consider indexing the element as VARCHAR. When an XPath contains a text code or a one-word entry, you are often looking for an exact match between the search string and the entire content of the XPath; an application that searches an XPath like this will often provide a list of values to choose from. This type of information is better handled with the VARCHAR data type; the exact match will be faster and the content of an XPath will consume less space in the database than if the same content was indexed as STRING.
However, all values stored in an XPath indexed as VARCHAR must be no more than 254–256 characters long depending on the database. Attempts to store an XML document will fail if the document includes an XPath that is indexed as VARCHAR and the content of the XPath is too long.
Text indexing is better suited for searching XPaths containing text that can be freely entered by a person, even if the text isn't very long. The linguistic analysis performed with a text index may produce better results searching that type of content than traditional searches against a character column.
An XML column's full document text index lets you find a word anywhere in the document. Sometimes a search needs to be more focused than that. For example, if the XML column contains information describing different GIS resources and you want to be able to find all work your organization produced for a project, you might include an element describing the purpose of the resource in the XPath index, and searches by project would look for references to the project name only in that element. This may make searches by project more accurate if the words used in project names may be used in different contexts. Elements describing concepts like the purpose of a resource are typically best handled by database text indexes.
Both VARCHAR and STRING XPaths can be searched using wildcard characters, but the wildcard character supported by the database may be different for these two data types in the same database. Also, the way in which wildcard characters can be used and the performance of the search may be different for each data type. Check your database documentation to determine what characters can be used as wildcards and how they can be used. For XPaths indexed as STRING, you may not need to use wildcard characters if stemming is performed during text indexing; if stemming is not performed and wildcard characters are used often in searches, consider adding this capability to your XML column's text indexes to improve search performance.
Indexing numbersIf an XPath contains numbers, indexing them as DOUBLE lets you evaluate their contents numerically. For example, if an element contained the scale denominator of the source data for a feature, such as 24,000, you would be able to find all features whose source data was at a scale greater or less than a given value.
If an XPath's data type is DOUBLE in the XML column's index definition but a document contains text in that XPath instead, the document will be stored successfully, but the value in that XPath won't be included in the XPath index and a conflict will be recorded in the geodatabase. An error noting this conflict will appear in an ArcSDE service log file if verbose logging is enabled for the geodatabase.
For the element containing the scale denominator of the source data, the value "24000" will index successfully but the values "1:24000" and "1/24000" will not. The presence of the colon (:) and slash (/) characters means the values can't be manipulated as numbers. Similarly, for elements containing the percent cloud cover in an image or the cost of a resource that are indexed as DOUBLE, the values "10%" or "$50" would not be indexed and conflicts would be recorded.
In contrast, if a value will be indexed as text and a document contains a number in that metadata element, the number will be handled as text; a conflict won't be recorded.
The XPath index definition file
An XPath index is defined using a text file that contains a general description of the index definition and a list of XPaths. A default index definition file is not provided; the contents of an XML column's XPath index depend entirely on the nature of the XML documents it contains and their intended use.
The anatomy of an index definition fileThe following example is an excerpt from an XPath index definition used with a collection of documents that describe GIS resources. The individual components of the index definition file are described below.
DESCRIPTION: ISO 19115 metadata collection index
##TAG
LOCATION PATH: /metadata/dataIdInfo/idPurp
DESCRIPTION: Purpose of the resource
DATA TYPE: STRING
EXCLUSION: FALSE
END
##TAG
LOCATION PATH: /metadata/distInfo/ditributor/distorFormat/formatName
DESCRIPTION: Format of the resource
DATA TYPE: VARCHAR
EXCLUSION: FALSE
END
##TAG
LOCATION PATH: /metadata/dataIdInfo/tpCat/TopicCatCd/@value
DESCRIPTION: Topic category code
DATA TYPE: DOUBLE
EXCLUSION: TRUE
END
In this example, an XML element containing information about the purpose of the resource is added to the database text index; longer text authored by a person is better indexed in this manner. An XML element containing the format of the data, map, service, or other resource is added to the character string index; short, brief text is better indexed in this manner, particularly if the values originate from a fixed domain and you want to search the XML column for an exact match. Also, an XML attribute containing a numeric code identifying the theme of the resource, such as agriculture, oceans, or transportation, is ready to be indexed as a number but is currently excluded from the XPath index.
- XPath index description—The purpose of the XPath index. If present, the description must be provided on the first line in the file following the text "DESCRIPTION:". Descriptions must be no longer than 64 characters in length; longer text will be truncated to 64 characters.
- Set of tags—A list of XPaths, or tags, whose contents can be searched. Each tag must be defined by a set of properties that are preceded by a line with the text "##TAG" and are followed by a line with the text "END". No other text can be present on either of these lines; they signify the beginning and ending of the list of properties that define a tag.
Each tag can have the following properties. Only one property can be defined on each line. Tag properties can be defined in any order.
- Tag location—An XPath that identifies the absolute location of an XML element or attribute in an XML document; other parts of an XML document cannot be indexed. When an XML document is stored, if an element or attribute in the document has an XPath that exactly matches the XPath of a tag in the XML column's index definition, its content will be indexed. This property is mandatory and must be provided on a line beginning with the text "LOCATION PATH:".
The XPath must begin with a forward slash (/) followed by the document's root element, and it must not use XML namespaces. If an XPath includes an asterisk (*) to identify a set of nodes or square brackets ([]) to include subqueries that conditionally select tags, attempts to create an XPath index on an XML column will fail.
XPaths must be 254–256 characters in length or less, depending on the database being used. If an index definition has an XPath longer than is supported by your database, attempts to create an XPath index for an XML column will fail.
- Tag description—A brief overview of the information contained by the tag. Descriptions are optional. They may help someone edit the index definition later. Descriptions must be no longer than 64 characters in length; longer text will be truncated to 64 characters. If provided, this information must be on a line beginning with the text "DESCRIPTION:".
- Tag data type—A value indicating how to index the tag's content. Valid values are STRING, VARCHAR, or DOUBLE; these indexing options are discussed in detail in the sections above. A data type is optional. If provided, this information must be on a line beginning with the text "DATA TYPE:". If not provided, the tag's content will be indexed as STRING and included in the text index.
- Tag exclusion—A value indicating if the tag's content should be included in or excluded from the XPath index. Valid values are FALSE or TRUE. When FALSE, the tag is included in the XPath index and its content is indexed. When TRUE, the tag's definition is stored in the geodatabase but is excluded from the XPath index, and its content will not be indexed. While prototyping or modifying a client application, it can be helpful to keep a tag in the index definition even though it isn't currently being used.
An exclusion value is optional. If provided, this information must be on a line beginning with the text "EXCLUSION:". If not provided, the tag will be included in the XPath index.
Modifying the XPath index
You can change an XML column's index definition at any time. To do so, modify the index definition file by adding, removing, excluding, or modifying tags as appropriate. For example, if you want to change a client application to add new search criteria, you must add the corresponding XPaths to the index definition file.
Next, you must alter the XML column's index definition using the updated file. The index definition recorded in the sde_xml_index_tags table is modified, leaving existing tags alone or modifying them and adding or removing tags as appropriate.
Then, the indexed values in the XML index table must be updated. If tags are added or if existing tags have their data type changed, all documents in the XML column will be opened and examined and values in those tags will be indexed properly. Values associated with tags that have been removed will be removed from the XML index table. If any existing tags remain the same, their indexed values will remain untouched.
Afterwards, the text index associated with the XPath index must be updated to reflect any changes. The full document text index will remain unchanged.
Many properties of an XML column affect how indexing and searching function and perform in different ways.
The performance of your client applications and the database itself can be affected by how you elect to configure and maintain the XML column's content. After reviewing the information below, you should work with your database administrator and integrate database maintenance tasks that are specific to your XML column with other routine database maintenance operations in a way that best suits your organization.
Storing XML documentsXML columns will be stored compressed in the database by default; this is the recommended storage option. However, you might choose to store XML documents uncompressed to make them available to other database applications; this can be accomplished by changing the DBTUNE configuration parameters used at the time an XML column is created. However, when stored uncompressed, XML documents consume more storage space and returning the documents found by searches will be slower because of the larger volume of data that must be handled.
When new documents are stored in an XML column, the original copy of the document is stored. A copy of the document is created and all XML markup is removed, then the remaining content from the document is stored for inclusion in the full document index. The original document is checked to see if it contains any XPaths included in the XPath index definition, if one exists. If so, the values of those XPaths are extracted and indexed.
Storing a large number of XML documents at once can impact the performance of your application and the database. If you know a large number of documents will be added or updated at once, consider planning for that operation to occur when there is less demand on the database such as in the early morning or the evening.
Indexing and searching XML documentsAfter a document is stored, it can be searched immediately using XPaths indexed as VARCHAR and DOUBLE. For the full document index and XPaths indexed as STRING, the database may not immediately process and analyze the new text and then update its text indexes; documents can't be searched with criteria based on these indexes until their information has been included in them. There are two aspects to consider in determining when you will be able to find new documents using the text indexes: when updates to the text indexes will begin and how long they will take.
When the text indexes are updated depends on the database and how it is configured for text indexing. Different databases have different options that determine when text indexes are updated. Some databases automatically update the text indexes by default; others require updates to be started manually, though typically you can create a scheduled job to start the updates at a given time or after a given interval.
It is important to note that if the database updates the indexes automatically, the indexes may not be updated immediately; the database typically chooses an appropriate time to index the text based on the amount of resources that are available. If your database doesn't automatically update the text indexes, you may be able to use DBTUNE configuration parameters to override the default settings and define a time or interval when the text indexes will be updated for your XML column; otherwise you will have to use the database's tools to create and schedule a text indexing job.
Follow the recommendations provided in the database documentation regarding the best method or time interval for updating text indexes in your database. If no clear recommendations are made, schedule text index updates to occur nightly. The text indexing process can consume a lot of database resources; running this operation during the day could slow down many applications depending on the database.
The length of time required to update the text indexes depends on the amount of database resources available, the amount of text in each XML document, the number of XPaths indexed as STRING and how much text they contain, the total number of new or modified documents in the XML column, and how text indexing is configured for that XML column. Indexing the text during off-peak hours will complete more quickly if more database resources are available when other applications are not being used.
By default, text indexes will typically be configured for incremental updates. This means the database tracks changes that have been made to the XML column's documents. Only documents that are new or have changed since the last update to the text indexes will be processed the next time the text indexes are updated. It is not recommended to change this behavior; changing this would require processing all documents every time the text indexes are updated, which would take a significantly longer time.
If you perform a type of linguistic analysis and index the results in advance, searches using that type of linguistic analysis will be faster. For example, adding indexes to support wildcard searches will make those searches faster. Adding more indexes for more types of linguistic analysis may produce faster and better search results, but the trade-off is that indexing will take more time because more processing must be done in advance. Keep this in mind when determining the text indexing configuration you want to use for your XML column.
While it may be desirable to update the text indexes more than once a day, this is not generally advisable. If you choose to update the text indexes more than once a day, carefully consider the length of time required to update the text indexes when determining the time interval between updates. You should not start one update before the previous one has finished or try to start one update immediately after the previous one has completed. There is no way to know what resources will be available, how much text must be updated, or what other operations will be affected at a given time.
If you choose to update text indexes frequently while you are prototyping a client application, be sure to change the settings for your XML column to be appropriate for a production database before deploying your application. DBTUNE configuration parameters are only applied at the time an XML column is created. Changes to an XML column's settings, such as when its text indexes will be updated, must be handled directly in the database.
The safest and most reliable method is to schedule text index updates nightly at an appropriate time in relation to other scheduled database maintenance operations.
Optimizing the database text indexesThe more often text indexes are updated, the faster they become fragmented. The more fragmented the text indexes are, the more the performance of searches on those indexes will degrade. Even if an XML column is updated nightly, the indexes will become fragmented over time. When the number of documents in an XML column has increased by approximately 25 percent, the text indexes should be optimized to reduce fragmentation and restore their optimal search performance.
Depending on how your XML column is used and how often its contents change, you may want to automate optimizing its text indexes by scheduling a task in the database for this operation. For example, you might optimize the indexes monthly if that time interval is appropriate for your data. If a database doesn't support optimizing text indexes as a specific type of task, you can get similar results by completely rebuilding the text index, that is, reprocessing all documents in the XML column; this may be referred to as full population.
You should optimize text indexes during off-peak hours.
Consult the database documentation to learn more about text indexing options and updating, optimizing, and rebuilding full text indexes.
XML columns can be created and managed using ArcObjects. If you are using an Enterprise geodatabase, they can also be created and managed using the sdexml administrative command. These methods do not share the same options for managing XML columns.
Custom code written using ArcObjects can store XML documents in an XML column, create and modify an XPath index for an XML column, search the documents in an XML column using the XPath index, and update the database text indexes to include the information in new XML documents.
The sdexml administrative command lets you view individual documents in an XML column, create and modify an XPath index for an XML column, and provide statistics about the published documents and indexed XPaths. For Oracle databases only, an XML column's database text indexes can also be optimized; you can continue searching an XML column while the indexes are being optimized. See the ArcSDE administrative command reference for details about using the sdexml command.
NOTE: The sdexml administrative command is only available if you are using an Enterprise geodatabase.
For XML columns created to support an ArcIMS Metadata Service, ArcIMS provides additional utilities to create and modify an XPath index, update and optimize the database text indexes, and report conflicts where documents contain text in an XPath indexed as DOUBLE. See the ArcIMS help system for more information.

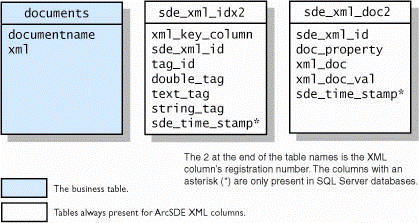 To see further details on the tables used to track XML columns in the database, see the following topics:
XML columns in a geodatabase stored in DB2XML columns in a geodatabase in InformixXML columns in a geodatabase stored in OracleXML columns in a geodatabase stored in PostgreSQLXML columns in a geodatabase in SQL Server
For information on configuration parameters that control the storage of these tables, see DBTUNE configuration parameter name-configuration string pairs.
ArcSDE for Oracle includes two scripts to help you configure your database to store XML data. See Tuning an Oracle instance for XML data storage for details.
To see further details on the tables used to track XML columns in the database, see the following topics:
XML columns in a geodatabase stored in DB2XML columns in a geodatabase in InformixXML columns in a geodatabase stored in OracleXML columns in a geodatabase stored in PostgreSQLXML columns in a geodatabase in SQL Server
For information on configuration parameters that control the storage of these tables, see DBTUNE configuration parameter name-configuration string pairs.
ArcSDE for Oracle includes two scripts to help you configure your database to store XML data. See Tuning an Oracle instance for XML data storage for details.