Topology in ArcGIS
Topology in ArcGIS
|
| Release 9.3 |
   |
In geodatabases, topology is the arrangement that defines how point, line, and polygon features share coincident geometry. For example, street centerlines and census blocks share common geometry, and adjacent soil polygons share their common boundaries.
Topology defines and enforces data integrity rules (for example, there should be no gaps between polygons). It supports topological relationship queries and navigation (for example, navigating feature adjacency or connectivity), supports sophisticated editing tools, and allows feature construction from unstructured geometry (for example, constructing polygons from lines).
Addressing topology is more than providing a data storage mechanism. In ArcGIS, topology includes all of the following six aspects:
- The geodatabase includes a topological data model using an open storage format for simple features (i.e., feature classes of points, lines, and polygons), topology rules, and topologically integrated coordinates among features with shared geometry. The data model includes the ability to define the integrity rules and topological behavior of the feature classes that participate in a topology.
- ArcGIS includes topology layers in ArcMap that are used to display topological relationships, errors, and exceptions. ArcMap also includes a rich set of tools for query, editing, validation, and error correction of topologies.
- ArcToolbox includes a comprehensive set of geoprocessing tools for building, analyzing, managing, and validating topologies.
- ArcGIS includes advanced software logic to analyze and discover the topological elements in the feature classes of points, lines, and polygons. This includes a rich set of tools to validate, discover, identify, edit, and resolve both the topological graph and the feature coordinates. These tools are heavily used throughout ArcGIS for many workflows and tasks.
- ArcMap includes a rich editing and data automation framework that is used to create, maintain, and validate topological integrity and to perform shared feature editing.
- ArcGIS software logic is available in the Desktop, Engine, and Server that can navigate topological relationships, work with adjacency and connectivity, and assemble features from these elements. For example, identify the polygons that share a specific common edge; list the edges that connect at a certain node; navigate along connected edges from the current location; add a new line and "burn" it into the topological graph; split lines at intersections; and create resulting edges, faces, and nodes.
Elements of a geodatabase topology
In a geodatabase, the following properties are defined for each topology:
- The name of the topology to be created.
- The cluster tolerance used in topological processing operations. The cluster tolerance is often a term used to refer to two tolerances: the x,y tolerance and the z-tolerance. The default value for the cluster tolerance is 10 times the coordinate resolution. Refer to the "Cluster processing" section below for more information.
- List of feature classes. First you need a list of the feature classes that will participate in a topology. All must be in the same coordinate system and organized into the same .
- The relative accuracy rank of the coordinates in each feature class. If some feature classes are more accurate than others, you will want to assign a higher coordinate rank. This will be used in topological validation and integration. Coordinates of a lower accuracy will be moved to the locations of more accurate coordinates when they fall within the cluster tolerance of one another. Features with the highest accuracy should receive a value of 1, less accurate feature classes a value of 2, even less accurate feature classes a value of 3, and so on.
- A list of topology rules for how features share geometry. Here is a section that describes the topology rules available in ArcGIS.
Topology editing and validation in ArcMap
In ArcMap, there is a special map layer for a topology that is used to display errors in a topology for editing and for showing topology status (edited areas to be validated called
dirty areas).
There is also a rich editing environment and workflow for topologies in ArcMap. See
About topology editing for more information.
Topology rules define the permissible spatial relationships between features. The rules you define for a topology control the relationships between features within a feature class, between features in different feature classes, or between subtypes of features.
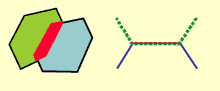
For example, the rule Must not overlap is used to manage the integrity of features in the same feature class. If two features overlap, the overlapping geometries are displayed in red (such as shown by the overlapping red area in the adjacent polygons and the linear segment of the two lines below).
Topology rules can also be defined between subtypes of feature classes. For example, suppose you have two subtypes of street line features—normal streets (those that connect to other streets at both nodes) and cul-de-sac streets (those that dead-end at one node). A topology rule can require street features to be connected to other street features at both ends, except in the case of streets belonging to the cul-de-sac subtype.
Using your features' spatial relationships and behavior to define topology rules
Spatial relationships express specifically how features share coincident geometry along with the rules for the behavior of their spatial representations. For example, some common spatial relationships and rules include
- Parcels cannot overlap. Adjacent parcels have shared boundaries.
- Stream lines cannot overlap and must connect to one another at their endpoints.
- Adjacent counties have shared edges. Counties must completely cover and nest within states.
- Adjacent census blocks have shared edges. Census blocks must not overlap, and census blocks must completely cover and nest within block groups.
- Road centerlines must connect at their endpoints.
- Road centerlines and census blocks share coincident geometry (edges and nodes).
Here is a conceptual view of spatial relationships and integrity rules that can be managed using a topology. In the first column on the left, you can see some common relationships and rules that can be defined between features in the same feature class. In the three right-hand columns, you can see rules that can be defined between two feature classes.
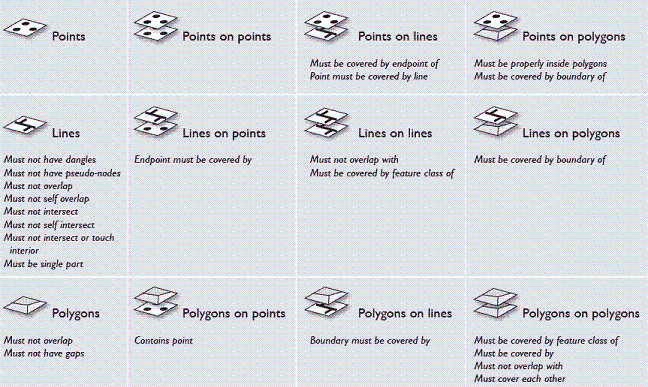
Each of these situations defines a potential case for using topology rules to maintain data integrity.
Learning more about topology rules
Learn more about
topology rules.
View a
poster illustrating topology rules in ArcGIS.
Validation performance and the effect of rules
Topology validation is compute-intensive—the larger the number of vertices that have to be processed, the more time will be required for the validation process to complete (e.g., minutes for datasets containing hundreds of thousands of features and hours for a dataset containing around 10 million features). Increasing the number of rules in your topology will not significantly increase the processing time for validation.
The initial validation of the topology checks all the features in the participating feature classes in a topology. This check can take some time, but subsequent checks are performed only on the areas that have been edited. These are called "dirty areas."
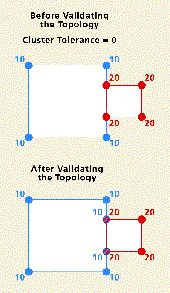
Creating topological relationships involves analyzing the coordinate locations of feature vertices among features in the same feature class as well as between the feature classes that participate in the topology. Those that fall within a specified distance of one another are assumed to represent the same location and assigned a common coordinate value (i.e., they are colocated).
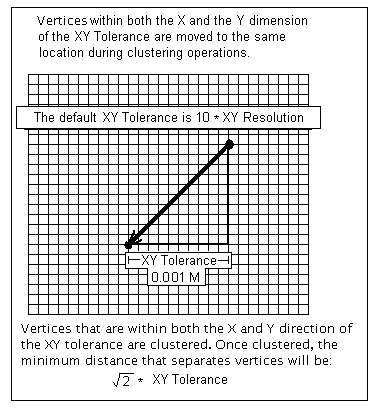
A cluster tolerance is used to integrate vertices. All vertices that are within the cluster tolerance may move slightly in the validation process. The default cluster tolerance is based on the precision defined for the dataset. The default cluster tolerance is 0.001 meters in real-world units. It is 10 times the distance of the x,y resolution (which defines the amount of numerical precision used to store coordinates).
Two cluster tolerances: x,y tolerance and z-tolerance
In ArcGIS, a
pair of cluster tolerances is used to integrate vertices:
- An x,y tolerance to find vertices within the horizontal distance of one another.
- A z-tolerance to distinguish whether or not the z-heights or elevations of vertices are within the tolerance of one another and should be clustered.
How coordinates are clustered (colocated)
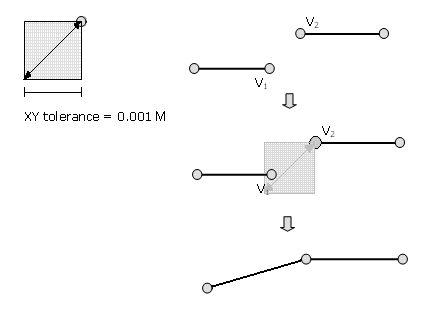
The x,y tolerance should be small, so only vertices that are very close together (within the x,y tolerance of one another) are assigned the same coordinate location. When coordinates are within the tolerance, they are said to be coincident and are adjusted to share the same location.
In this way, the x,y tolerance also defines the distance a coordinate can move in x or y (or both) during clustering. Therefore, coordinates can be clustered if they are within the x,y tolerance in
either the x or the y dimension. See the diagram below. Coordinates can move as much as represented by the diagonal line in the graph, which forms a triangle. If you remember your geometry and the Pythagorean Theorem, the maximum distance within which coordinates are clustered is equal to the SQRT of 2 times the x,y tolerance.
NOTE: The Pythagorean Theorem states that in a right triangle, the square of the hypotenuse (the longest side) is equal to the sum of the squares of the other two sides (legs).
The default x,y tolerance
The default x,y tolerance is set to 0.001 meter or its equivalent in the units of the dataset's coordinate system. For example, if your coordinate system is recorded in feet, the default value is 0.003281 foot (0.03937 inch). The default value is 10 times the default x,y resolution, and this is recommended for most cases. If coordinates are in latitude-longitude, the default x,y tolerance is 0.0000000556 degree.
Algorithms used in validation and clustering
When a vertex of one feature in the topology is within the x,y tolerance of an edge of any other feature in the topology, the topology engine creates a new vertex on the edge to allow the features to be geometrically integrated in the clustering process.
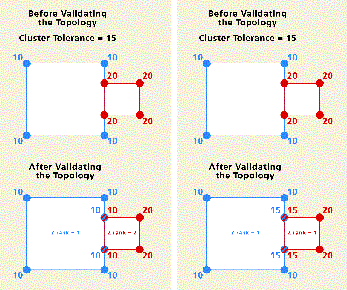
When clustering feature vertices during topology validation, it is important to understand how the geometry of features is adjusted. All vertices of any feature class that participates in a topology can potentially be moved if they fall within the x,y tolerance of another vertex. Vertices with higher coordinate rank features will move less and exert more gravitational pull on lower-ranked coordinates. Vertices of equal-ranked features will be geometrically averaged.
It is important to note that the x,y tolerance is not intended to be used to generalize geometry shapes. Instead, it's intended to integrate line work and boundaries during topological operations, which means to help discover features that are coincident and whose vertices are the same location. This will integrate (colocate) coordinates that fall within the x,y tolerance of one another. Because coordinates can move in both x and in y by as much as the cluster tolerance, many potential problems can be resolved by processing datasets with commands that use the cluster tolerance. These include handling of extremely small overshoots or undershoots, automatic sliver removal of duplicate segments, and coordinate thinning along boundary lines.
Maximum movement of vertices
The clustering process works by moving across the map, identifying clusters of coordinates that fall within the x,y tolerance of one another. ArcGIS uses this algorithm to discover, clean up, and manage coincident geometry between features. This means that the coordinates of the coincident geometric elements are colocated (snapped to the same location). This is fundamental to many GIS operations and concepts.
As a result of the clustering process, feature vertices can potentially move more than the cluster tolerance in two ways.
- The tolerance is used to calculate both a horizontal distance as well as a vertical distance to find coordinates with the tolerance. The maximum distance a coordinate could move to its new location during this operation is SQRT of 2 times the x,y tolerance. See the "How coordinates are clustered" section and the clustering diagram above.
- The clustering algorithm is iterative. So it is possible in some cases that once vertices are moved, they will fall within the cluster tolerance of other vertices and can shift more than the SQRT of 2 times the x,y tolerance. This is very slight and will only occur when there are vertices that fall very close to, but not quite within, the cluster tolerance of one another (for example, within 0.001 meters of one another). As coordinate vertices are moved slightly with each iteration, they can be clustered with other coordinates and then shift across the map more than the tolerance.
Useful tips
Here are some useful tips for cluster tolerances:
- Generally, you can use an x,y tolerance that is 10 times the x,y resolution and expect very good results.
- A typical x,y tolerance is orders of magnitude smaller than the true accuracy of your data capture. For example, while your feature coordinates may be accurate to 2 meters, the default x,y tolerance is 0.001 meter.
- To keep movement small, keep the x,y tolerance small. However, an x,y tolerance that is too small (such as 2 times x,y resolution or less) may not properly integrate the line work of coincident boundaries.
- Conversely, if your x,y tolerance is too large, feature coordinates may collapse on one another. This can compromise the accuracy of feature boundary representations.
- Your x,y tolerance should never approach your data capture accuracy (sometimes referred to as map accuracy standards). For example, at a map scale of 1:12,000, one inch equals 1,000 feet, and 1/50 of an inch still equals 20 feet on the ground—a data capture accuracy that would be hard to meet during digitizing and scan conversion. You'll want to keep the coordinate movement using the x,y tolerance well under these numbers. Remember, the default x,y tolerance in this case would be 0.003281 foot, which should work well in almost any situation.
- In topologies, you can set the coordinate accuracy rank of each feature class. You'll want to set the coordinate rank of your most accurate features (such as your surveyed features) to 1 and of less accurate features to 2, 3, and so on, in descending levels of accuracy. This will cause other feature coordinates with a higher rank number (and therefore, a lower coordinate accuracy) to be adjusted to the more accurate features with a lower rank number.
- Often, you will want to be able to control which feature classes are more likely to be moved in the clustering process. For example, when features in one feature class are known to have more reliable positions than another set of features, you may want the less reliable features to snap to the more reliable ones. Ranks are assigned to the feature classes in the topology to accommodate this common situation. Vertices of lower-ranking features within the cluster tolerance will be snapped to nearby vertices of higher-ranking features. Locations of vertices of features of equal rank that lie within the cluster tolerance will be geometrically averaged.
NOTE: First, please read the "Cluster processing" section above if you are not familiar with how coordinate ranks are used in topology validation operations.
The coordinate accuracy ranks you specify for feature classes in a geodatabase topology control the movement of feature vertices during validation. The rank helps control how vertices are moved when they fall within the cluster tolerance of one another. Vertices within the cluster tolerance of one another are assumed to have the same location and are colocated (the same coordinate values are assigned for the coordinates that fall within the cluster tolerance).
When different feature classes have a different coordinate accuracy, such as when one was collected by survey or differential global positioning system (GPS) and another was digitized from a less accurate source, coordinate ranks can allow you to ensure that reliably placed vertices are the anchor locations toward which less reliable vertices are moved.
Typically, the less accurate coordinate is moved to the location of the more accurate coordinate, or a new location is computed as a weighted average distance between the coordinates in the cluster. In these cases, the weighted average distance is based on the accuracy ranks of the clustered coordinates.
For more information about how accuracy ranks are set for each feature class, see Coordinate accuracy ranks. The location of equally ranked vertices are geometrically averaged when they are within the cluster tolerance of each other.
Be sure to assign ranks in the proper order. The features with the highest accuracy get a rank of 1, less accurate a rank of 2, and so on.
This table provides an example for setting four accuracy levels. If you cannot distinguish between the accuracy of two feature classes, assign them the same rank.
Assigning coordinate ranks in a topology| Locational accuracy of coordinates |
Rank |
|---|
| Most accurate |
1 |
| Moderately accurate |
2 |
| Low accuracy |
3 |
| Lowest |
4 |
| And so on |
|
Z cluster tolerance and ranks
Feature classes that model terrain or buildings three dimensionally have a
representing elevation for each vertex. Just as you control how features are snapped horizontally with x,y cluster tolerance and ranks, if a topology has feature classes that model elevation, you can control how coincident vertices are snapped vertically with the z cluster tolerance and ranks.
The z
defines the minimum difference in elevation, or z-value, between coincident vertices. Vertices with z-values that are within the z cluster tolerance are snapped together during the Validate Topology process.
If you're modeling city buildings, two buildings may be adjacent to one another and appear to share a common edge in the x,y domain. If elevation values for building corners were collected using photogrammetry, you should be concerned about maintaining the relative height of each building structure during the topology validation process. By setting the z cluster tolerance to a value of zero, you can prevent z-values from clustering when you validate topology.
If you're modeling terrain, you may have datasets collected with different x,y and z accuracies. In this case, you may want to set a z cluster tolerance greater than zero to allow snapping. To avoid z-values collected with a high level of accuracy snapping to z-values of lower accuracy, you can assign each feature class a rank. Lower-ranked features' z-values snap to the elevation of higher-ranked vertices if they fall within the cluster tolerance. Z-values of vertices belonging to feature classes of the same rank are averaged if they fall within the cluster tolerance.
The validate topology process averages and snaps z-values in such a way that each z-value adjusts by a total amount that is not more than the z cluster tolerance. This causes z-values of vertices with the same x,y to average or snap into groups.
For example, if the z cluster tolerance is 5, z-values of these six coincident vertices average into two groups, 11.25 and 3.5:
| Vertex |
Before validate |
After validate |
| z0 (rank = 1) |
12.5 |
11.25 |
| z1 (rank = 1) |
10 |
11.25 |
| z2 (rank = 1) |
7.5 |
3.5 |
| z3 (rank = 1) |
5 |
3.5 |
| z4 (rank = 1) |
2.5 |
3.5 |
| z5 (rank = 1) |
0 |
3.5 |
In the following example, the coincident vertices have different ranks and the cluster tolerance is 5. Z-values average and snap into three groups, 22.5, 7.5, and 1.25:
| Vertex |
Before validate |
After validate |
| z0 (rank = 1) |
25 |
22.5 |
| z1 (rank = 1) |
20 |
22.5 |
| z2 (rank = 1) |
7.5 |
7.5 |
| z3 (rank = 2) |
5 |
7.5 |
| z4 (rank = 2) |
2.5 |
1.25 |
| z5 (rank = 2) |
0 |
1.25 |
Z cluster tolerance values can range from zero to the extent of the z domain (maximum z-value–minimum z-value).
Ranks are a relative measure of accuracy. The difference in rank of two feature classes is irrelevant, so ranking them 1 and 2 is the same as ranking them 1 and 3 or 1 and 10.
If your geodatabase is version 8.3 or earlier, the z cluster tolerance is not available to you. Upgrade your geodatabase to make use of the z cluster tolerance.
Topology validation, errors, and exceptions
Once you've created a new topology or made edits to a feature that participates in a topology, the next step is to
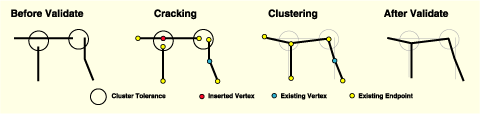
validate the topology. Validating the topology involves the following four processes:
- Cracking and clustering of feature vertices to find coincident features that share the same locations (have common coordinates).
- Inserting common coordinate vertices into coincident features that share geometry.
- Running a set of integrity checks to identify any violations of the rules that have been defined for the topology.
- Creating an error log of potential topological errors in your feature dataset.
In ArcMap, during editing, you can validate the whole topology, the visible extent of your map, or a selected area. You can also validate the whole topology in ArcCatalog and in geoprocessing.
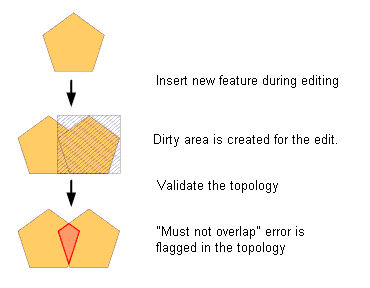
As you edit or change your data, ArcGIS will track changed areas and flag them as dirty. Validate will only be run against the dirty areas in your topology. If no edits or updates have been made since the previous validate, there is nothing to check.
Errors and exceptions
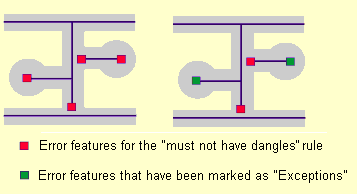
Violations of topology rules are initially stored as errors in the topology. Error features record where topological errors were discovered during validation. Certain errors may be acceptable, in which case the error features can be marked as exceptions. Errors and exceptions are stored as features in the topology layer and allow you to render and manage the cases in which features need not adhere to the topology rules.
ArcMap and ArcCatalog allow you to create a report of the errors and exceptions for the feature classes in your topology. You can use the report of the number of error features as a measure of the data quality of a topological dataset. The error inspector in ArcMap lets you select different types of errors and zoom to individual errors. You can correct topology errors by editing the features that violate the topology's rules. After you validate the edits, the error is deleted from the topology.
Where appropriate, you can use editing tools to find and fix errors using the Fix Topology Error tool (which works much like a spell-checker).
This tool allows you to select a topology error and choose from a number of fixes that have been predefined for that error type. You can also use the tool to get more information about the rule that has been violated or mark the error as an exception.
Geodatabase topologies are flexible enough to handle exceptions to the topology rules. You can also mark errors as exceptions. Exceptions are thereafter ignored, although you can return them to error status if you decide that they are actually errors and that the features should be modified to comply with the topology rules.
Exceptions are a normal part of the data creation and update process. For example:
An assessor's geodatabase might have a topology rule requiring that building features not cross parcel lines as a quality control for the building digitizing effort. This rule might be true for almost all cases, but it could be violated by some exceptions such as high-density housing and commercial buildings.
If you create a condominium building feature that crosses parcel boundaries, it will be flagged as an error when you validate your edits, but you can mark it as an exception to the rule.
As in the diagram shown above, a street database for a city might have a rule that centerlines must connect at both ends to other centerlines. This rule would normally ensure that street segments are correctly snapped to other street segments when they are edited. However, at the boundaries of the city, you might not have street data. Here the external ends of streets might not snap to other centerlines. These cases could be marked as exceptions, and you would still be able to use the rule to find cases where streets were incorrectly digitized or edited.
See
Correcting topology errors for more information.
Dirty areas and validation
A key goal of geodatabase topologies is to optimize the time spent on processing and validating the feature data that participates in a topology before it can be used. Generally speaking:
- Feature classes that participate in a topology are always available for use regardless of the state of the topology.
- Topology validation is user driven. You decide when and how often you want to validate (i.e., rebuild) the topology (for example, after every edit operation or less frequently such as at the end of each edit session).
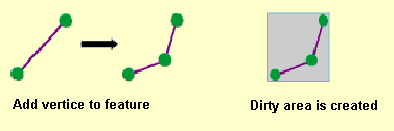
- All edits made to each feature class are tracked so that only the areas in which changes have been made need to be revalidated. These changed areas are called "dirty areas."
Dirty areas are areas that have been edited, updated, or affected by the addition or deletion of features. Dirty areas allow the topology to limit the area that must be checked for topology errors during topology validation. Dirty areas track the places where new features have been added or existing features modified. This allows selected parts, rather than the whole extent of the topology, to be validated.
Dirty areas automatically managed for you by ArcGIS
Dirty areas are created by ArcGIS when a feature that participates in a topology is created or deleted, a feature's geometry is modified, a feature's subtype is changed, versions are reconciled, the topology properties are modified, or the geodatabase topology rules are changed.
Version reconciliation acts like other edits and updates to a feature class—the changed areas are flagged as dirty.
Schema changes, such as adding a new topology rule, imply that the whole topology must be revalidated (i.e., the whole dataset is flagged as dirty).
Information stored in a geodatabase topology
The following information is stored as part of a geodatabase topology:
- The topology definition. This includes a schema record of all the properties specified when you created the topology.
See the Elements of a topology design for more information on the list of properties.
- Common coordinate vertices for all features that share coincident geometry. The Validate operation integrates coordinates using clustering to identify common vertices among the features and feature classes. In each case, the vertices identified as having the same location are written out as coordinates for all the features they belong to in all feature classes. These are the features that "share geometry," and they do so through their common coordinates.
NOTE: These shared coordinates are used by a geodatabase topology to rapidly discover and query the topology graph of edges, nodes, and faces and their feature relationships for various operations in ArcGIS.
- A table. This contains areas covering features that have been added or edited as well as areas for reconcile updates from versioning.
- Three tables of topology error features are saved in the topology by the Validate operation:
- Point errors
- Line errors
- Area errors
The geometry of the topological error is written to one of these error tables along with information about the feature classes involved and the topology rule that has been violated.
Errors that you flag as exceptions are also recorded in the error feature tables. An Exceptions column flags errors that you identify as exceptions. In other words, an exception is an error with the exceptions column check on. Errors and exceptions are tracked as you update and maintain the feature dataset and topology through time.
See
Topology validation, errors, and exceptions for more information.
Topologies and feature datasets
A topology is built on a set of feature classes that are held within a common feature dataset. Each new topology is added to the feature dataset in which the feature classes and other data elements are held.
When you create the topology, you can specify any subset of the feature classes from the feature dataset to participate in the topology according to the following conventions:
- A topology can reference one or more feature classes from the same feature dataset.
- A feature dataset can have more than one topology.
- However, a feature class can only belong to one topology.
- A feature class cannot belong to a topology and a geometric network.
- However, a feature class can belong to a topology and either a network dataset or a terrain dataset.
